Distilling What & Why: Enhancing Driver Intention Prediction with MLLMs
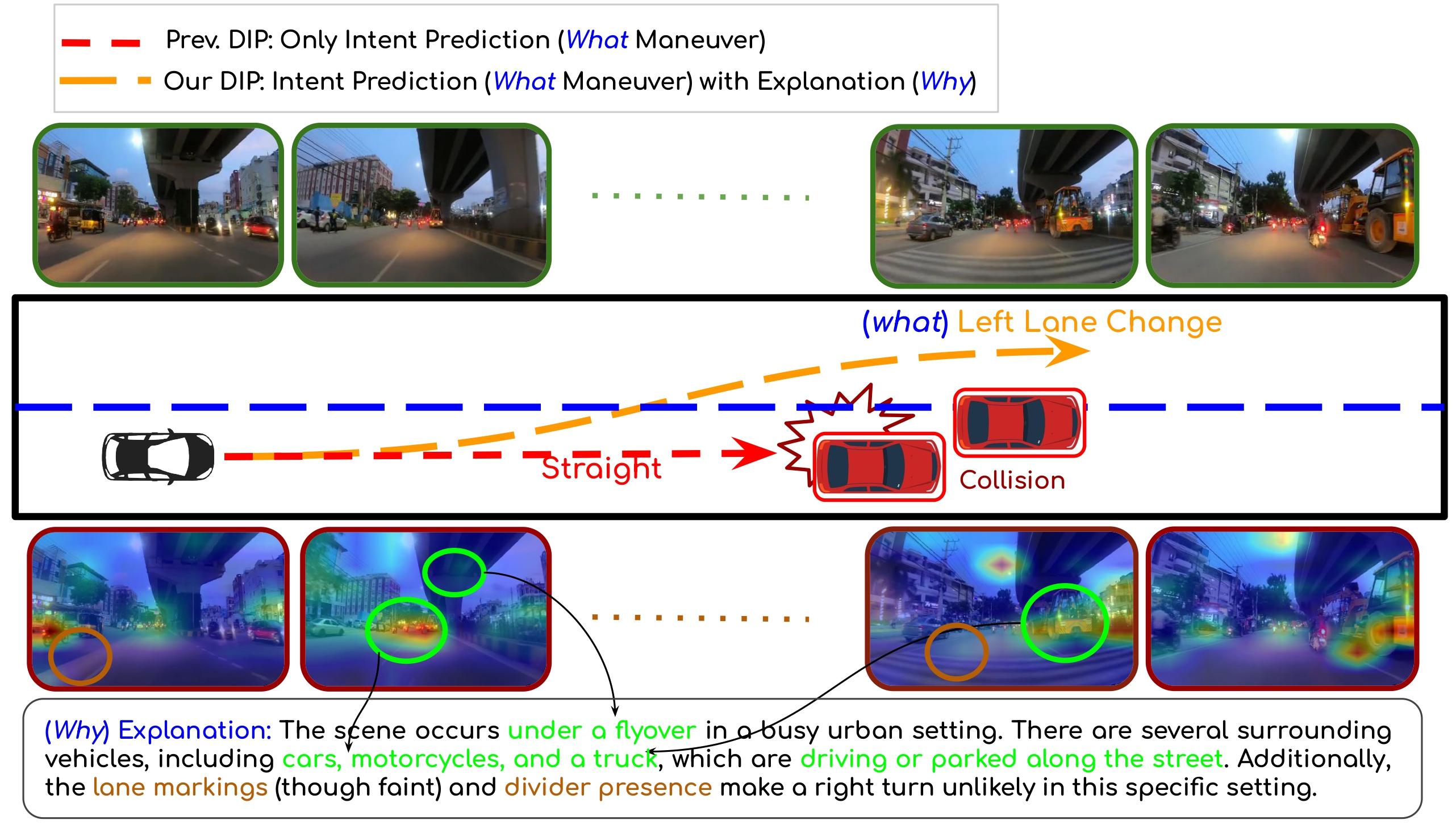
Illustration of a driving scenario where the ADAS vehicle predicts a left lane change (what) to avoid slower traffic ahead (why). Existing driver intent prediction models lacking reasoning may miss such cues, while our framework jointly learns and distills both maneuver and explanation, improving decision quality.
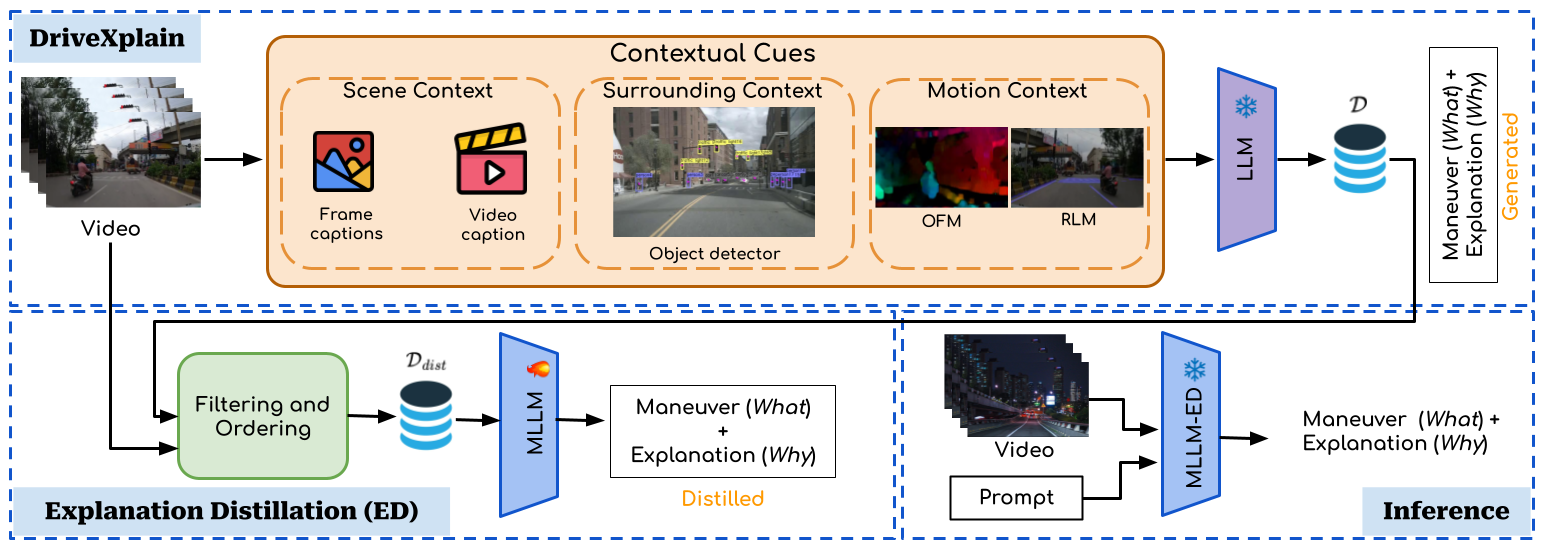
Our proposed framework for the DIP task. DriveXplain generates natural language explanations alongside maneuvers and Explanation Distillation distills these explanations into a single MLLM to enhance DIP performance at inference.
Why DriveXplain?
Autonomous systems must predict what surrounding drivers will do and explain why to build trust. DriveXplain aligns perception, prediction, and natural-language reasoning so safety teams can audit decisions in real time.
- Multi-view vision transformers capture nuanced spatial-temporal cues.
- Multimodal LLMs convert latent features into human-friendly explanations.
- A calibrated intent prior enforces scene-level consistency and safety rules.
Method
- Contextual Perception — Fuse 360° video, LiDAR, map priors, and CAN bus signals via spatio-temporal attention.
- Intention Decoder — Predict lane changes, stops, yields, and merges with uncertainty-aware forecasting.
- Why Module — A lightweight instruction-tuned LLM references salient agents, traffic signals, and semantics to articulate why.
Results
Get in touch
Please feel free to reach us out.
Corresponding Author: avijit.dasgupta@research.iiit.ac.in
@inproceedings{drivexplain2026,
title = {Distilling What and Why: Enhancing Driver Intention Prediction with MLLMs},
author = {Sainithin Artham, Avijit Dasgupta, Shankar Gangisetty, C. V. Jawahar},
booktitle = {WACV},
year = {2026}
}This website is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. This means you are free to borrow the source code of this website, we just ask that you link back to this page in the footer.